
宾夕法尼亚大学 计算机与信息科学硕士
LLaMA-2 的 fine-tuning 教程来啦:Uranus:如此简单!LLaMA-2 finetune 实战!
LLM 这两周不断带给我们震撼与惊喜。GPT-4 的发布让大家对 LLM 的想象空间进一步扩大,而这些想象在本周眼花缭乱的 LLM 应用发布中逐渐成为现实,随便举一些例子:
GitHub Copilot Xgithub.blog/2023-03-22-github-copilot-x-the-ai-powered-developer-experience/
https://www.adobe.com/sensei/generative-ai.htmlwww.adobe.com/sensei/generative-ai.html
而 LLM 相关的开源社区这两周也涌现了很多优秀的工作,吸引了很多人的关注。其中,我比较关注的是 Stanford 基于 LLaMA 的 Alpaca 和随后出现的 LoRA 版本 Alpaca-LoRA。原因很简单,便宜。
https://github.com/tloen/alpaca-loragithub.com/tloen/alpaca-lora
Alpaca 宣称只需要 600$ 不到的成本(包括创建数据集),便可以让 LLaMA 7B 达到近似 text-davinci-003 的效果。而 Alpaca-LoRA 则在此基础上,让我们能够以一块消费级显卡,在几小时内完成 7B 模型的 fine-turning。
下面是开源社区成员分享的可以跑通的硬件规格及所需时间:
| GPU 规格 | Epochs | 训练耗时 (h) |
|---|---|---|
| RTX 4070 Ti 12GB | 2 | 9.8 |
| RTX 4080 16GB | 2 | 5.5 |
| RTX 4090 24GB | 2 | 4 |
| 2 * RTX 3090Ti 24GB | 3 | 4.5 |
根据大家分享的信息,fine-tune 7B 模型**仅需要 8-10 GB vram。**因此我们很有可能可以在 Google Colab 上完成你所需要的 fine-tune!
那么,说干就干!

为什么要训练自己的 ChatGPT ?
我想到了以下的方面:
- 对我个人而言,这非常非常 cooooool !
- 让模型能够讲我熟悉的语言
- 让模型替我写注释和测试代码
- 让模型学习产品文档,帮我回答用户提出的小白问题
- …
计划
那么,为了训练自己的 Chat我们需要做那些事儿呢? 理论上需要如下步骤:
第一步:准备数据集
fine-tune 的目标通常有两种:
- 像 Alpaca 一样,收集 input/output 生成 prompt 用于训练,让模型完成特定任务
- 语言填充,收集文本用于训练,让模型补全 prompt。
以第一种目标为例,假设我们的目标是让模型讲中文,那么,我们可以通过其他 LLM (如 text-davinci-003)把一个现有数据集(如 Alpaca)翻译为中文来做 fine-tune。实际上这个想法已经在开源社区已经有人实现了。
第二步:训练并 apply LoRA
在第一步准备的数据集上进行 fine-tune。
第三步:合并模型(可选)
合并 LoRA 与 base 可以加速推理,并帮助我们后续 Quantization 模型。
第四步:quantization(可选)
最后,Quantization 可以帮助我们加速模型推理,并减少推理所需内存。这方面也有开源的工具可以直接使用。
实践
柿子挑软的捏,我们从简单的目标开始:让模型讲中文。
为了达成这个目标,我使用的数据集是 Luotuo 作者翻译的 Alpaca 数据集,训练代码主要来自 Alpaca-LoRA。
准备
由于我打算直接使用 Alpaca-LoRA 的代码,我们先 clone Alpaca-LoRA:
git clone git@github.com:tloen/alpaca-lora.git
下载数据集:
wget https://github.com/LC1332/Chinese-alpaca-lora/blob/main/data/trans_chinese_alpaca_data.json
创建虚拟环境并安装依赖(需要根据不同环境的 cuda 版本调整):
conda create -n alpaca python=3.9
conda activate alpaca
cd alpaca-lora
pip install -r requirements.txt
训练
单卡选手很简单,可以直接执行:
python finetune.py \ --base_model 'decapoda-research/llama-7b-hf' \ --data_path '/path/to/trans_chinese_alpaca_data.json' \ --output_dir './lora-alpaca-zh'
双卡选手相对比较麻烦,需要执行:
WORLD_SIZE=2 CUDA_VISIBLE_DEVICES=0,1 torchrun \ --nproc_per_node=2 \ --master_port=1234 \ finetune.py \ --base_model 'decapoda-research/llama-7b-hf' \ --data_path '/path/to/trans_chinese_alpaca_data.json' \ --output_dir './lora-alpaca-zh'
在我的环境下(2 * RTX 3090 Ti 24GB),需要额外配置 micro_batch_size 避免 OOM。
--micro_batch_size 2
推荐的其他额外参数:
--num_epochs 2
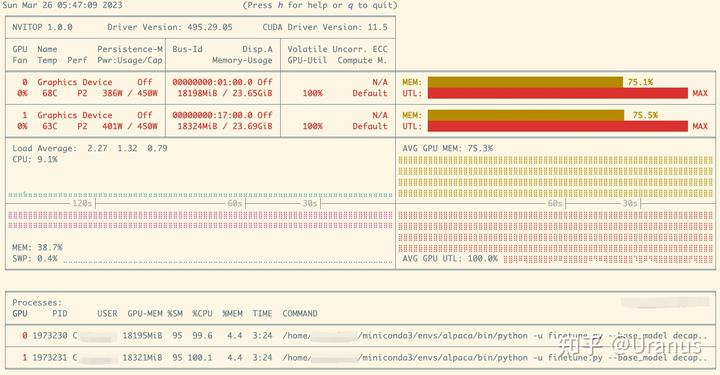
训练的过程比较稳定,我在训练过程中一直在用 nvitop 查看显存和显卡的用量:
下面是我训练时模型收敛的情况,可以看到差不多 2 epochs 模型就收敛的差不多了:
| Epoch | Eval loss |
|---|---|
| 0.52 | 1.13 |
| 1.03 | 1.08 |
| 1.55 | 1.05 |
| 2.06 | 1.04 |
| 2.58 | 1.03 |
推理
单卡选手可以直接执行:
python generate.py --base_model "decapoda-research/llama-7b-hf" \
--lora_weights './lora-alpaca-zh' \
--load_8bit
双卡选手还是会麻烦点,由于现在还不支持双卡推理,我手动修改了 generate.py,添加了第 47 行:

而后,执行上面的命令即可。
如果你的推理运行在服务器上,想要通过其他终端访问,可以给 launch 方法添加参数:
server_name="0.0.0.0"
此时打开浏览器,享受你的工作成果吧 ![]()
加速推理
Alpaca-LoRA 提供了一些脚本,如 export_hf_checkpoint.py 来合并模型。合并后的模型可以通过 llamap.cpp 等项目达到更好的推理性能。
测试
最后,让我们对比下原生 Alpaca 与自己 fine-tune 的 Alpaca,看看 fine-tune 到底有没有让模型学会讲中文吧!
Good Examples
| Instruction | Input | Output (Alpaca) | Output (Ours) |
|---|---|---|---|
| Alpaca 是什么?与 llama 的区别是什么? | N/A | Alpaca is a domesticated species of South American camelid, related to the llama. Alpacas are smaller than llamas and have finer, softer wool than llamas. | Alpaca是一种羊类动物,与 llama 有些相似,但它们不是一种同一种物种。 |
| 找出以下文章的主旨 | 气候变化是一个越来越具有争议的全球性问题。它已经对环境和人类生活产生了极大的影响。我们已经看到极端天气事件和海平面上升的增加,这 两者都对地球产生了重大影响。 | The main theme of the article is that climate change is a global issue that has had a significant impact on the environment and human life. We have seen extreme weather events and sea level rise, both of which have had a major impact on the planet. | 文章的主旨是气候变化对环境和人类生活产生了极大的影响。 |
Bad Examples
| Instruction | Input | Output (Alpaca) | Output (Ours) |
|---|---|---|---|
| 写一段程序完成以下目标 | 打印字典中所有的键值对 | def print_dictionary(dictionary): for key, value in dictionary.items(): print(key, value) | 打印字典中所有的键值对: 打印字典中所有的键值对: ...... |
可以看出模型确实在讲中文,也能依据中文的指令和输入完成一些工作。但是由于 LLaMA 本身训练数据大部分为英文以及 Alpaca 数据集翻译后的质量不足,我们的模型有些时候效果不如原生 Alpaca。此时不得不感叹**高质量数据对 LLM 的重要性**。
总结
作为一个分布式系统方向的工程师,fine-tune 一个 LLM 的过程遇到了不少问题,也有很多乐趣。虽然 LLaMA 7B 展现出的能力还比较有限,我还是很期待后面开源社区进一步的工作。
后续我也打算尝试 fine-tune 特定目的的 LLM,比如让 LLM 教我做饭,感兴趣的朋友可以保持关注!