SCUTOSC BBS
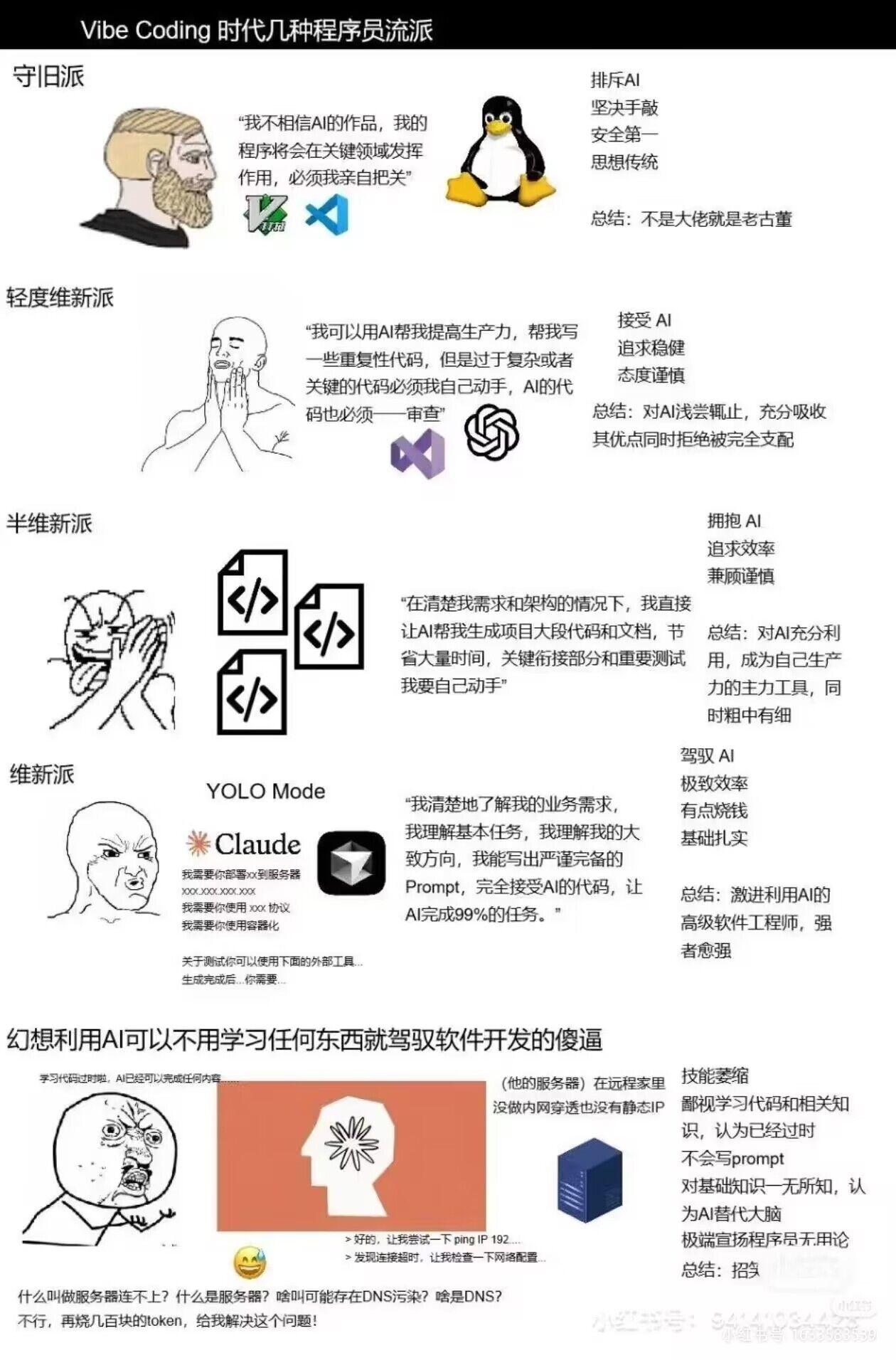
论 vibe coding 的程序员流派
灌水人生
ai-agent
c-w-xiaohei
2026 年3 月 24 日 05:28
1
N3Q`0TDB9Q3_Y)8913U%4N
1260×1912 230 KB